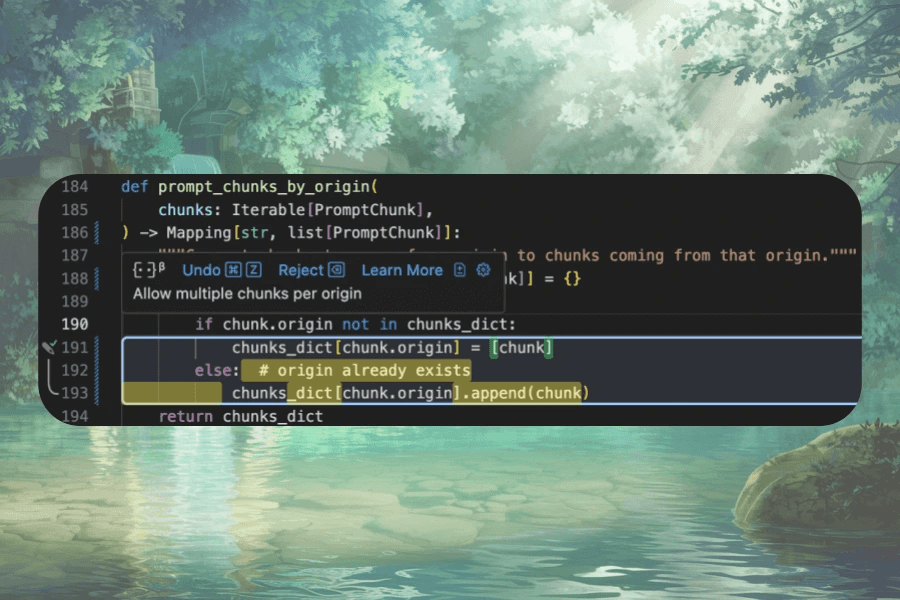
TL;DR: At Augment, we're pushing the boundaries of developer AI with our newest and most sophisticated feature to date: Next Edit. In this blog post, we'll dive deep into the AI challenges we faced—figuring out user intent, determining where to make changes, and executing those changes—and how we overcame them to build Next Edit.
Next Edit extends code completions beyond the cursor and across your entire workspace. It understands what you're trying to accomplish and works in the background to suggest edits that help you complete your tasks more quickly and comprehensively.
See Next Edit in action:
[embed wista]
Why Was Next Edit Hard to Build?
For us, extending completions beyond the cursor was a no-brainer. But doing so in a way that really kept developers in the flow was trickier than anticipated. We had to solve three distinct research challenges:
- Figuring Out What Tasks the User Is Trying to Accomplish
- Determining Where to Make Those Changes
- Figuring Out How to Make the Edits
These problems are complex due to the dynamic and often non-linear nature of coding workflows, the scale of modern codebases, and the need for speed and accuracy. Let's delve into each of these challenges and explore how we addressed them.
1. Figuring Out What Tasks the User Is Trying to Accomplish
Understanding the user's intent is one of the hardest problems in AI, especially in a coding environment where user activity is rarely simple.
The Challenge
- Non-linear Editing Histories: Developers' coding workflows are often non-linear and complex. They might copy a block of code, paste it elsewhere, and immediately modify it significantly. They might also make multiple edits in rapid succession, frequently switching between files or functions, or undo and redo changes as they experiment with different implementations. These non-linear workflows create a messy trail of changes that can mislead a model trying to infer the developer's true intent.
- Unintended Biases: Naively sampling training data by splitting the diff hunks in a given task can introduce unintended biases into the model. For example, the model might learn to avoid touching parts of the codebase that already contain recent changes. This is problematic because those areas might be precisely where further edits are needed.
- Intention Hallucination: Models might hallucinate intentions, suggesting changes that are not directly related to the user's recent edits. This occurs when the model tries to be overly proactive, aiming to cover all possible relevant edits (high recall), which can result in noisy and disruptive suggestions. Conversely, if the model is too conservative—focusing only on suggestions it is highly confident about (high precision)—it may become passive, missing opportunities to assist the developer. There's a delicate balance between being "helpful but noisy" and "accurate but passive."
Our Solution
We carefully designed a data pipeline to synthesize common user interactions from GitHub commits and pull requests (PRs). This involved:
- Simulating Common Editing Scenarios: By analyzing commit messages, initial commit states, and final commit states, we developed a sophisticated algorithm to simulate realistic editing scenarios that reflect common developer behaviors. This allowed us to create training data that closely mirrors the complexities of actual coding workflows.
- Optimizing Diff Granularity: We taught our models to read fine-grained editing events while carefully optimizing the granularity of diffs presented in the prompt. If the model sees diffs that are too fine-grained, it may become distracted by the noise in the user’s editing history. If it sees diffs that are too coarse, it struggles to distinguish newer changes from older ones. By balancing the granularity, we enabled the model to effectively interpret the context of changes without being misled by noisy editing histories.
- Avoiding Undoing User's Recent Changes: We found that the model sometimes had a strong tendency to undo the user's recent changes, which could lead to a frustrating experience. To address this, we made special efforts to improve our training samples to discourage this behavior. By carefully curating the training data, we ensured the model respects the user's latest edits and focuses on providing helpful suggestions without overwriting recent work.
The Outcome
By simulating realistic user interactions and carefully designing our training data, we improved the model's ability to accurately infer user intent without being misled by messy editing histories. This allows Next Edit to provide relevant and helpful suggestions that align with what the user is trying to accomplish.
2. Figuring Out Where to Make Those Changes
Identifying where to apply changes across an entire codebase is a monumental task, especially with large monorepos containing tens of thousands of files.
The Challenge
- Scalability: The localization mechanism needs to be scalable to handle big codebases efficiently without consuming excessive resources.
- Speed: It needs to be extremely fast to support highly interactive usage patterns, providing immediate suggestions as the user makes new changes.
- Relevance: It must accurately identify relevant locations without overwhelming the user with unnecessary suggestions or missing important ones.
Our Solution
Unlike prior approaches that relied heavily on large language models to make navigation decisions (like OpenDevin), we took a different path:
- Fast Localization with a Trained Retriever: By combining our retrieval infrastructure with a retriever model specifically designed to identify code locations likely to require updates, we achieved both speed and accuracy. The model uses the current context to efficiently locate relevant files and code sections.
- Efficiency and Scalability: This approach is highly scalable and can be run on large monorepos containing tens of thousands of files without significant performance degradation.
- Editing Surrounding Code: The code around the user's cursor is always added to the list of candidate locations and processed first, ensuring immediate and contextually relevant suggestions.
The Outcome
By using a retrieval-based approach, we achieved a localization mechanism that is both scalable and fast. This allows Next Edit to efficiently identify where changes should be made across large codebases, providing timely and relevant suggestions without slowing down the development process.
3. Figuring Out How to Make the Edits
Once we've figured out what the user is trying to do and where changes need to be made, the final challenge is determining how to make those edits accurately and efficiently.
The Challenge
- Complex Edits Beyond Cursor Insertions: Existing models are not good at making edits that involve large-scale changes beyond simple insertions next to the user's cursor.
- Latency Constraints: Generating these edits should be fast, allowing for real-time suggestions without significant latency. Naively generating large numbers of tokens would make the feature too slow for practical use.
- Codebase Awareness: Suggestions need to match the project's coding standards, conventions, and correctly use custom APIs, requiring the model to be aware of the entire codebase context.
Our Solution
We developed innovative techniques to overcome these challenges:
- Novel Diff Decoding Scheme: We taught the model a specialized diff format that is both compact and unambiguously applicable to the original code. This format allows the model to represent complex edits succinctly, minimizing the number of tokens generated and enabling efficient processing of large files. This reduces the latency from several seconds to hundreds of milliseconds.
- Codebase-Aware Suggestions: We leveraged our powerful Retrieval Augmented Generation (RAG) infrastructure, previously used in our completion and chat features, to add codebase-specific context to Next Edit. By retrieving relevant pieces of the codebase, the model can make suggestions that align with project-specific coding standards and correctly interact with custom APIs. This ensures that the edits are not only aligned with what the user is trying to accomplish but also consistent with existing APIs and coding patterns, resulting in suggestions that are both accurate and cohesive within the codebase.
The Outcome
Our approach allows the model to generate accurate and contextually appropriate edits quickly. By combining an efficient decoding scheme with codebase-aware context retrieval, Next Edit provides high-quality suggestions without sacrificing speed.
Conclusion
Building Next Edit meant tackling three core AI challenges: capturing developer intent amid messy editing histories, pinpointing relevant changes across huge codebases, and generating accurate edits with minimal latency. Our solutions—a specialized location model, deep codebase retrieval, and a novel diff decoding scheme—enable seamless, context-aware updates that go well beyond manual cursor placements. Check out our side-by-side comparison with screen recordings to see how Next Edit stacks up against Cursor’s Tab feature.
We're now working on scaling up Next Edit to handle larger-scale changes, from enhancing the model's ability to understand broader contexts and dependencies to supporting bulk edits across many files simultaneously. We're also exploring deeper integration with our chat functionality, which could provide additional context for edit suggestions and enable more interactive problem-solving workflows.
We're continuing to learn from real-world usage patterns and edge cases as developers use Next Edit in their daily work. If you're interested in trying Next Edit or discussing the technical details of our approach, we'd love to hear from you.
Written by

Jiayi Wei
Jiayi Wei is a research scientist at Augment, specializing in enhancing model quality for the Code Completion and Next Edit features. He graduated with a PhD in Computer Science at the University of Texas at Austin, working with Isil Dillig and Greg Durrett on applying deep learning to emerging programming tasks such as probabilistic type inference and code auto-editing.

Arun Chaganty
Arun Chaganty is a research scientist at Augment Computing, where he works on new AI features like Next Edit. Previously, he worked on conversational AI at Google Research, led the Conversations AI team at Square, Inc. and was Head of AI at Eloquent Labs. He graduated with a PhD in computer science at Stanford University, working with Percy Liang and the Stanford NLP group.